
Feature flags in an AI World
Let’s Start Here
Tensorflow and SciKit are very common Python libraries used in Machine Learning (ML) and Artificial Intelligence (AI) processing. ML and AI have been all over the place in the news, and for good reason. These technologies are extremely powerful and useful for a broad range of problems, from friendly and intelligent AI chatbots all the way to sophisticated image processing and ‘deepfake’ generation. The question is not what can AI do, but what can’t it do? Where can’t it go?
One of the most common and well-tread use cases for AI/ML is recommendation systems, such as those used by big tech giants like Amazon and Netflix. The theory is that, using what you’ve previously purchased (or watched) we can then predict the next things you would like to purchase or watch based upon what other people purchased or watched.
In this article we will build a basic recommendation system. We will see examples in two common Python libraries, SciKit and Tensorflow. We will use Split to allow us to experiment with the parameters for these recommendation system models. This would allow us to explore which of the different parameters for the models better work for recommendations with that data (eg – what people actually do end up purchasing after being shown recommended items.)
The Data
The dataset we will use for this University of California – Irvine (UCI)’s freely available dataset called Online Retail. This dataset is of an online retail store that sells “unique all-occasion gifts.”
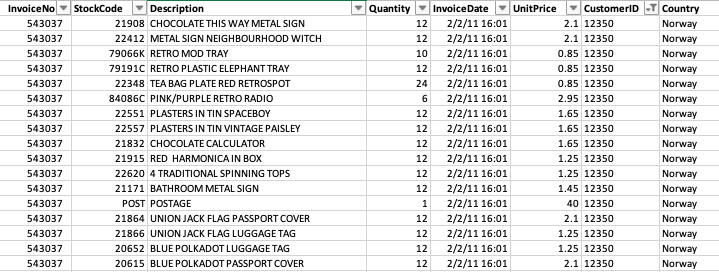
Here is an example of what it looks like:

With this data, based upon what a customer has purchased, we can attempt to predict what a different customer will likely purchase and recommend that to them.
SciKit
SciKit-Learn is a popular, free Python library that is used for machine learning. It contains a wealth of methods for common tasks such as supervised and unsupervised learning, dataset transformation, cross validation, and model selection and evaluation.
We will start by building a very basic pipeline using cosine similarity to get to a number that determines how similar individual items are to one another.
Imports
We can start by importing pandas, sklearn, scipi and numpy as these libraries are all required. We also import warnings to assist in building some helpful warning messages. pdist and squareform will also be used for comparing our cosine similarity to other methods, but we will get to that in a moment.
import sys
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial.distance import pdist, squareform
import warnings
import numpy as npReading the File and Setup
We will need to define a few things when we start. We are going to recommend some items for user 12350. This is what they’ve previously purchased:
This code does the following things. It sets the user ID, reads in the file, removes any rows without a customer ID or with a negative quantity – to simplify for this exercise we are not going to be handling the potential that an item gets returned.
We then create what we call a ‘product purchase count matrix.’ This is a way for us to have a data structure that holds the customer purchases. This will be used by Sci-Kit so that it can understand what users have purchased and compute what other items might be purchased.
# User id for which we want to make recommendations
userId = 12350.0
# Load the dataset (adjust the path to where you've saved the dataset)
df = pd.read_excel('Online Retail.xlsx')
# Remove rows without CustomerID and negative Quantity
df = df[pd.notnull(df['CustomerID']) & (df['Quantity'] > 0)]
# Create a product purchase count matrix
purchase_matrix = df.groupby(['CustomerID', 'Description']).agg({'Quantity': 'sum'}).unstack().fillna(0)
purchase_matrix = purchase_matrix['Quantity']We will then fed this into the cosine similarity function.
# Consider all purchased items
purchase_matrix = (purchase_matrix > 0).astype(int)
# Calculate cosine similarity between items
item_similarity = cosine_similarity(purchase_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=purchase_matrix.columns, columns=purchase_matrix.columns)
The last part is to then create a function that takes in the purchase matrix and returns the top n similar items to what the user has already purchased. We then proceed to print out those recommended items.
def recommend_items(customer_id, purchase_matrix, item_similarity_df, n_recommendations):
"""
Recommends items to a customer based on their purchase history and item similarity.
Args:
customer_id (int): The ID of the customer.
purchase_matrix (pandas.DataFrame): The purchase matrix containing customer-item purchase history.
item_similarity_df (pandas.DataFrame): The item similarity matrix.
n_recommendations (int): The number of recommendations to generate.
Returns:
list: A list of recommended items for the customer.
"""
# Get purchased items by the customer
purchased_items = purchase_matrix.loc[customer_id]
purchased_items = purchased_items[purchased_items > 0].index.tolist()
# Sum the similarity scores of the purchased items
similarity_scores = item_similarity_df[purchased_items].sum(axis=1)
# Remove already purchased items
similarity_scores = similarity_scores.drop(purchased_items)
# Get top N recommendations
recommendations = similarity_scores.sort_values(ascending=False).head(n_recommendations).index.tolist()
return recommendations
# Example: Recommend 5 items for customer with ID 12350.0
recommendations = recommend_items(userId, purchase_matrix, item_similarity_df, 5)
print(recommendations)
Running this code produces the top 5 items for user 12350.0 using cosine similarity.
['PLASTERS IN TIN WOODLAND ANIMALS', 'PLASTERS IN TIN CIRCUS PARADE ', 'PLASTERS IN TIN STRONGMAN', 'PLASTERS IN TIN SKULLS', 'BLUE HARMONICA IN BOX ']
However – let’s say we want to experiment by trying a few things.
- We want to try using a higher threshold for recommended items (eg – items that have been purchased 2 times or more)
- We want to try other similarity algorithms, such as pearson correlation or jaccard similarity
Feature Flag Setup
We are going to use feature flags for these 2 features. See their configuration below:

For the SimilarityAlgo flag we are going to use more than just on and off as treatments. See the following treatments we will use.
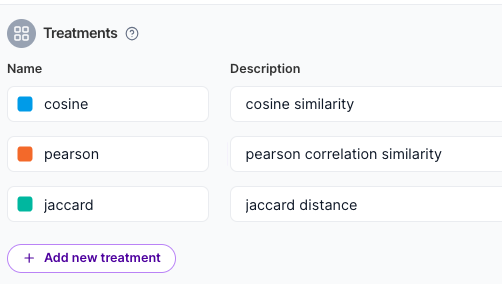
This will allow us to control the similarity algorithm used for the recommendation system.
Now, let’s see what the code looks like with Split imported and these feature flags added.
import sys
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial.distance import pdist, squareform
import numpy as np
from splitio import get_factory
from splitio.exceptions import TimeoutException
factory = get_factory('1t4ff5a6o3ocnmmmnqgaebpfm7kta7kqhgli', config={'impressionsMode': 'OPTIMIZED'})
try:
factory.block_until_ready(5)
except TimeoutException:
# The SDK failed to initialize in 5 seconds. Abort!
sys.exit()
split = factory.client()
# User id for which we want to make recommendations
userId = 12350.0
# Load the dataset (adjust the path to where you've saved the dataset)
df = pd.read_excel('Online Retail.xlsx')
# Remove rows without CustomerID and negative Quantity
df = df[pd.notnull(df['CustomerID']) & (df['Quantity'] > 0)]
# Create a product purchase count matrix
purchase_matrix = df.groupby(['CustomerID', 'Description']).agg({'Quantity': 'sum'}).unstack().fillna(0)
purchase_matrix = purchase_matrix['Quantity']
userHigherThreshold = split.get_treatment(userId, 'UseHigherThreshold')
# Convert purchase counts to 1s and 0s
if(userHigherThreshold == 'on'):
# only consider items that have been purchased more than once
purchase_matrix = (purchase_matrix > 1).astype(int)
elif(userHigherThreshold == 'off'):
# Consider all purchased items
purchase_matrix = (purchase_matrix > 0).astype(int)
elif(userHigherThreshold == 'control'):
# Consider all purchased items
purchase_matrix = (purchase_matrix > 0).astype(int)
similarityAlgo = split.get_treatment(userId, 'SimilarityAlgo')
if(similarityAlgo == 'cosine'):
# Calculate cosine similarity between items
item_similarity = cosine_similarity(purchase_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=purchase_matrix.columns, columns=purchase_matrix.columns)
elif(similarityAlgo == 'pearson'):
# Calculate Pearson correlation similarity between items
item_similarity_df = purchase_matrix.T.corr()
elif(similarityAlgo == 'jaccard'):
# Convert purchase_matrix to boolean (True for items purchased)
binary_purchase_matrix = purchase_matrix.astype(bool)
# Calculate Jaccard distance and then convert to similarity
jaccard_distances = pdist(binary_purchase_matrix.T.values, metric='jaccard')
jaccard_similarity = 1 - squareform(jaccard_distances)
# Convert to DataFrame for easier handling
item_similarity_df = pd.DataFrame(jaccard_similarity, index=purchase_matrix.columns, columns=purchase_matrix.columns)
else:
# Use cosine similarity as default
item_similarity = cosine_similarity(purchase_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=purchase_matrix.columns, columns=purchase_matrix.columns)
def recommend_items(customer_id, purchase_matrix, item_similarity_df, n_recommendations):
"""
Recommends items to a customer based on their purchase history and item similarity.
Args:
customer_id (int): The ID of the customer.
purchase_matrix (pandas.DataFrame): The purchase matrix containing customer-item purchase history.
item_similarity_df (pandas.DataFrame): The item similarity matrix.
n_recommendations (int): The number of recommendations to generate.
Returns:
list: A list of recommended items for the customer.
"""
# Get purchased items by the customer
purchased_items = purchase_matrix.loc[customer_id]
purchased_items = purchased_items[purchased_items > 0].index.tolist()
# Sum the similarity scores of the purchased items
similarity_scores = item_similarity_df[purchased_items].sum(axis=1)
# Remove already purchased items
similarity_scores = similarity_scores.drop(purchased_items)
# Get top N recommendations
recommendations = similarity_scores.sort_values(ascending=False).head(n_recommendations).index.tolist()
return recommendations
# Example: Recommend 5 items for customer with ID 12350.0
recommendations = recommend_items(userId, purchase_matrix, item_similarity_df, 5)
print(recommendations)
TensorFlow
Similarly to SciKit, tensorflow can be used to build a recommendation system. However, for this example we will not be using a similarity matrix. Instead, Tensorflow is designed to use neural networks. So we will train a neural network on the UCI Purchase data and use that to recommend items to users.
Code for a Neural Network Recommendation System
The code for the script to enable and use the neural network is below:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Dot, Flatten, Dense
from tensorflow.keras.optimizers import Adam
# set user id for which we want to make recommendations
userId = 12350.0
# Load the dataset
df = pd.read_excel('Online Retail.xlsx')
# Preprocessing
df = df[pd.notnull(df['CustomerID'])]
df = df[df['Quantity'] > 0]
df['CustomerID'] = df['CustomerID'].astype('int32')
# Mapping CustomerID and Description to integer indices
customer_ids = df['CustomerID'].unique().tolist()
product_descriptions = df['Description'].unique().tolist()
customer_id_to_index = {x: i for i, x in enumerate(customer_ids)}
product_description_to_index = {x: i for i, x in enumerate(product_descriptions)}
df['customer_index'] = df['CustomerID'].map(customer_id_to_index)
df['product_index'] = df['Description'].map(product_description_to_index)
# Prepare the dataset for training
X = df[['customer_index', 'product_index']].values
# Dummy variable as we're treating this as an implicit feedback problem
y = np.ones(len(X))
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
num_customers = len(customer_ids)
num_products = len(product_descriptions)
embedding_size = 50
# Input layers
customer_input = Input(shape=(1,), name='customer_input')
product_input = Input(shape=(1,), name='product_input')
# Embedding layers for customers and products
customer_embedding = Embedding(num_customers, embedding_size, name='customer_embedding')(customer_input)
product_embedding = Embedding(num_products, embedding_size, name='product_embedding')(product_input)
# Dot product of embeddings
dot_product = Dot(axes=1)([customer_embedding, product_embedding])
# Flatten and output layer
output = Dense(1, activation='sigmoid')(Flatten()(dot_product))
# Model
model = Model(inputs=[customer_input, product_input], outputs=output)
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
# Training the model
history = model.fit([X_train[:, 0], X_train[:, 1]], y_train, batch_size=64, epochs=2, validation_split=0.2)
def reccomend_items(user_index, model, product_indices, top_n=5):
# Get all unique product indices
all_product_indices = set(product_indices.values())
# Find products already purchased by the user
purchased_product_indices = set(df[df['customer_index'] == user_index]['product_index'].unique())
# Exclude purchased items
candidate_product_indices = np.array(list(all_product_indices - purchased_product_indices), dtype=np.int32)
# Prepare model inputs
user_input = np.array([user_index] * len(candidate_product_indices), dtype=np.int32)
product_input = candidate_product_indices
# Predict the likelihood of the user purchasing each candidate product
predictions = model.predict([user_input, product_input]).flatten()
# Get the indices of the top N recommendations
top_indices = predictions.argsort()[-top_n:][::-1]
# Convert indices back to product descriptions (or IDs) for the final recommendation
top_product_descriptions = [product_descriptions[index] for index in candidate_product_indices[top_indices]]
return top_product_descriptions
# Example customer index
customer_index = customer_id_to_index[userId]
# Get top 5 recommended products for the user
recommended_products = reccomend_items(customer_index, model, product_description_to_index, top_n=5)
print("Top 5 recommended products for user:")
print(recommended_products)
Now this is a fairly significant chunk of code. There are a lot of things here we could experiment with. For our purposes, let’s pick a few things of interest.
Parameterizing the Number of Epochs
The first, being the number of epochs used for fitting the data. This code as it stands currently uses 2 epochs:
history = model.fit([X_train[:, 0], X_train[:, 1]], y_train, batch_size=64, epochs=2, validation_split=0.2)
However, we can increase or decrease that as needed. In fact, for this we will want to use dynamic configuration to control the number of epochs from the Split UI.
Here, you can see the use of Split’s Dynamic configuration. We are holding the number of epochs within Split.
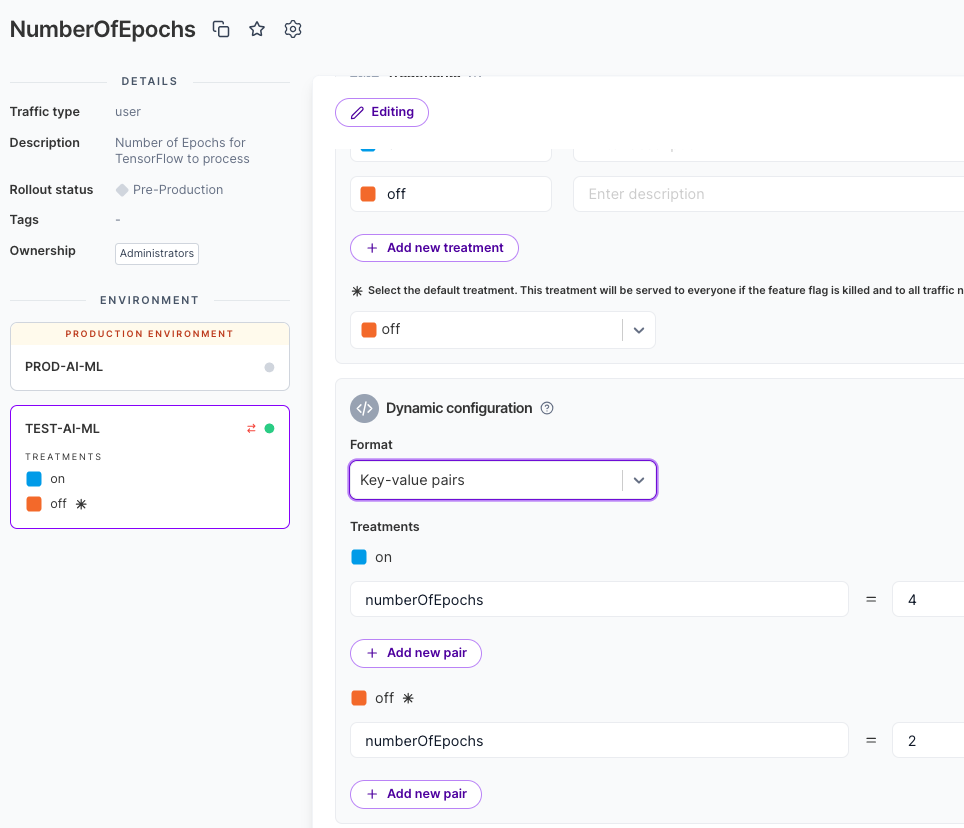
And we can reference it from the code in the following way:
# import split
from splitio import get_factory
from splitio.exceptions import TimeoutException
# import json
import json
#instantiate split
factory = get_factory('6lqv8j8a5v5bcslv7h96pud51qlrb12o240b', config={'impressionsMode': 'OPTIMIZED'})
try:
factory.block_until_ready(5)
except TimeoutException:
# The SDK failed to initialize in 5 seconds. Abort!
sys.exit()
split = factory.client()
# set user id for which we want to make recommendations
userId = 12350.0
epochsTreatment, raw_config = split.get_treatment_with_config(userId, 'NumberOfEpochs')
config = json.loads(raw_config) if raw_config is not None else {}
numberOfEpochs=int(config['numberOfEpochs'])
Then, we can take the numberOfEpochs variable and pass it into the model.
# Training the model
history = model.fit([X_train[:, 0], X_train[:, 1]], y_train, batch_size=64, epochs=numberOfEpochs, validation_split=0.2)
Activation Function
Finally, we can also experiment with a different activation function. Our current code uses sigmoid but we can try with ReLU (rectified linear unit) by passing in relu in this line of code.
# Flatten and output layer
output = Dense(1, activation='sigmoid')(Flatten()(dot_product))
Let’s make a flag for this.
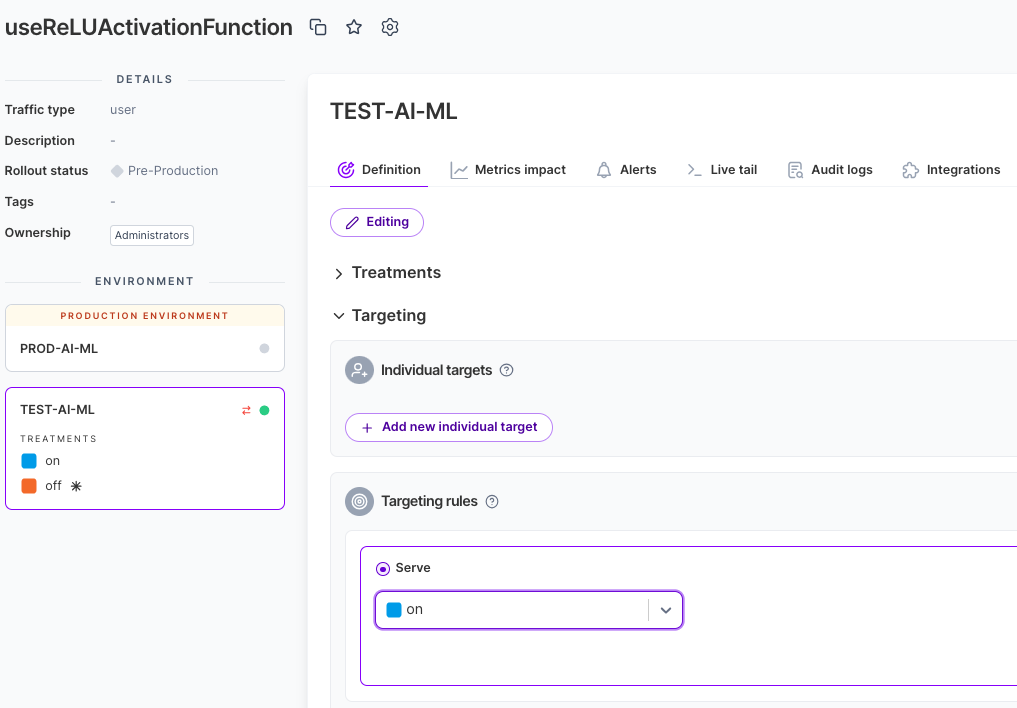
Now once we have that flag created, we can make the code look like this instead:
useReLU = split.get_treatment(userId, 'useReLUActivationFunction')
if(useReLU == 'on'):
activationFunction = 'relu'
else:
activationFunction = 'sigmoid'
# Flatten and output layer
output = Dense(1, activation=activationFunction)(Flatten()(dot_product))
In this way, we can control the activation function from Split, and experiment with how it affects application performance, as well as our recommendations and the resulting user experience, conversions, and other tracked events.
Future Experiments
With our flags in code, now we can proceed to do a percentage based rollout to look at metrics we might be interested in, such as time taken or CPU usage during the recommendation generation process.
With Split’s IFID functionality you will know which feature is impacting your metrics. There’s no guesswork about which feature affected which metric.
We can also experiment with using Split’s Dynamic Configuration to hold parameters used for more portions of the ML models within the feature flagging system itself.
Overall, feature flags allow us to have fine grained control over the recommendation generation process. We can use this for evaluation and testing of different approaches for an application, letting us use statistically proven methods to answer questions on application performance, user engagement, and much more.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Schedule a demo to learn more.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.