
Protect Your Database Continuously Using Feature Flags
One of the most, if not the most, critical piece of your web application stack is your database. And one of the very common times for it to be at risk is when you release new features. In this blog, we will explain how you can use feature flags to surgically release your feature safely while monitoring the impact of that specific feature on your database.
The World as We Know It
Most applications are made of a web or mobile client-side, server-side services and data stores, usually databases. Ideally, the application has an architecture where each service has its own data store, so that failures are isolated and performance can be well tested before production. However, applications are like organisms. They grow, they sprout, they evolve, and often a service ends up doing many things. Also, it can get very expensive to have too many separate services and too many separate data stores. Hence, it is often a balance to manage, and, commonly, services may share a database (though it is recommended they at least don’t share the data in it!).
In an ideal world, also, we manage very well all kinds of errors, including database slowness or unavailability, but it is easy to assume that is just there, or it can require a lot of effort to manage cases that are quite rare. And so we often take a few shortcuts because, well, we have a business to drive and features to build for that, and we need to get going. Life is always a balancing act, and business and engineering lives are no different.
In that world, anytime a database is affected, it usually has a strong business impact. For example, if you are an e-commerce company and your page performance is severely degraded, that can hurt your revenue significantly. Of course, it is even worse when the database is down. A B2B company likely has SLA agreements and a credit system when they don’t meet that SLA. In that case, a database outage can also cause serious financial damage. That’s not even counting the negative effect on the reputation of the company.
What Drives a Database Issue?
Everything can. And that is the challenge.
Of course, if you change a query and don’t hit an index, that could cause some stress on the database. It can also be just a change in the traffic pattern. For example, a call that was quite rarely done is now being made thousands of times per second. That kind of situation is not uncommon and can be driven by changes anywhere in the stack, from any service but also from the client side. Imagine the load implications of changes to a busy main page. You add information on that page and thousands of calls per second. If that information is made of multiple data pieces, that becomes thousands of calls. So every change is susceptible to change dramatically in your database situation.
How to Catch the Issue Before It Becomes an Incident?
Of course, start with testing. However, most of those issues are harder to find in staging because the traffic patterns and volumes are so different from production. You should be able to catch a query missing an index there, though. Just put a monitor on your database for that, most databases should have that information easily available.
Rate limiting is obviously a really good way to avoid things being damaged, but it would often kick in far in the rollout process and would still impact many users. However, it is still an important tool to use to protect your system. It might partially degrade the experience, but it avoids a much more serious outage.
Finally, you can use feature flags with measurement. First, add measurements around your database. You don’t necessarily need a lot. Just having the count of queries, the latency of queries, and the size of responses would likely be covering most of what you need. If you add it to your data access layer, it can be an easy addition, and you can quickly get that information for all your services and data interactions. To those, you add a few dimensions, such as the database name, the service, the hostname, and the table/collection—if the query was successful. Once you send those events to split, you can create several detailed metrics and alerts out of those events.
Here is a metric example from the Split metrics creation page:
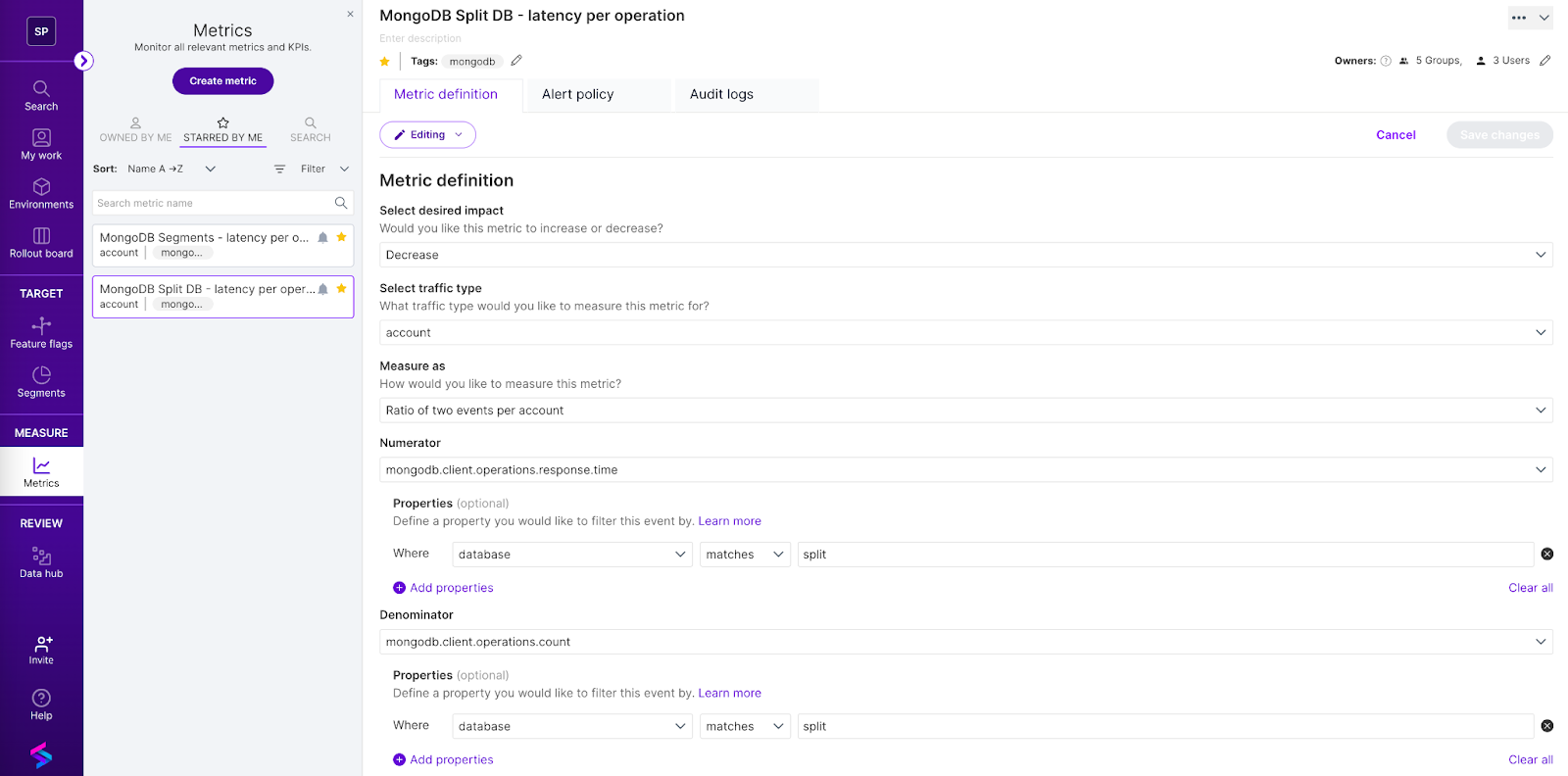
With your metrics in place in Split, you just roll out any of your feature flags. Client or server-side? It doesn’t matter; we automatically connect the event data to the feature flag data (we call those impressions) and join them together to tell you early on if the change behind the feature flag is significantly affecting your database metric. And that’s where things get great, because the person behind the change doesn’t even have to have to think about the database (though it would be better that they do!).
Those issues often happen because someone made what they thought was a benign change and didn’t realize the effect. With Split, both the person making the change and the people in charge of the database could be immediately alerted with only a low percentage of the traffic having the new feature (and before the whole traffic is turned on and the database suffers a much heavier load that could bring it down).
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.