
Retrieval Augmented Generation (RAG) is a technique used in Generative AI to be able to enhance a generative AI model with text retrieved from an additional source of information. This is typically used in situations where there is a domain specific information resource that is needed to augment the generative AI’s model, such as a company knowledge base or integrating data from proprietary APIs or data sets in order to enhance the accuracy and value provided by the AI.
The key components of this are the retrieval system and the generative model. They need to work together in order to successfully generate the augmented result from the query entered by the user.
How RAG Works
At a very high level, you can think of RAG working as a three step process. The first step is when the user inputs their query to the Generative AI system using RAG. After that, the retrieval system then needs to process this information to fetch the relevant information from the knowledge base or data set that it is supposed to use as ‘the truth’ for use in the Generative model. Then, after that, the generative model takes the fetched information and builds it into an answer.
OpenAI offers the ability to tell the GPT model to use custom functions that allow it to retrieve data on the fly. These would be used for enriching requests when the additional data to integrate with the GPT comes from private API data, as that is not necessarily static over long periods of time.
What is currently popular for storing and retrieving text similarity is to use vector databases for this purpose. Chunks of textual information are vectorized and then stored in a vector database. The vectorization process for documents used in a RAG pipeline is often referred to as creating ‘embeddings’ for them. This is the style of RAG we will be demonstrating in this article
Integrating information from the knowledge base or other data set has benefits for generative models. It allows improved accuracy and contextual relevance that would not be possible for a generative model to build with its training data alone. This is a quite common use case in the enterprise when you need to reduce or eliminate AI hallucinations and base answers on an existing, limited corpus of factual information.
An Example
Here’s an example of how a RAG might work. In this example we have an application that allows users to ask questions about great books in history. In this specific example we’ll source from Mark Twain’s ‘The Adventures of Tom Sawyer’
Python:
import requests
from openai import OpenAI
import os
import faiss
import numpy as np
from concurrent.futures import ThreadPoolExecutor
user_id = 'user123'
# Function to download text from Project Gutenberg
def download_text(url):
response = requests.get(url)
response.encoding = 'utf-8'
response.raise_for_status()
return response.text
# URL for "The Adventures of Tom Sawyer" from Project Gutenberg
url = 'https://www.gutenberg.org/files/74/74-0.txt'
text_file_path = 'tom_sawyer.txt'
index_file_path = 'tom_sawyer_index.faiss'
# Function to save text to a file
def save_text_to_file(text, file_path):
with open(file_path, 'w', encoding='utf-8') as file:
file.write(text)
# Function to split text into paragraphs
def split_into_paragraphs(text):
paragraphs = text.split('\n\n')
paragraphs = [p.strip() for p in paragraphs if p.strip()]
return paragraphs
# Ensure you have set your OpenAI API key
client = OpenAI(
api_key=os.getenv('OPENAI_API_KEY')
)
# Function to get embeddings for paragraphs
def get_embeddings(paragraphs):
embeddings = []
model_name = "text-embedding-ada-002"
def fetch_embedding(paragraph):
response = client.embeddings.create(input=paragraph, model=model_name)
return response.data[0].embedding
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(fetch_embedding, paragraphs))
return embeddings
# Check if the FAISS index already exists
if not os.path.exists(index_file_path):
# Download and save the text if it doesn't exist
if not os.path.exists(text_file_path):
text = download_text(url)
save_text_to_file(text, text_file_path)
# Read the downloaded text
with open(text_file_path, 'r', encoding='utf-8') as file:
text = file.read()
# Split the text into paragraphs
paragraphs = split_into_paragraphs(text)
# Generate embeddings for the paragraphs
embeddings = get_embeddings(paragraphs)
# Create a FAISS index
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
# Convert embeddings to a numpy array and add to the index
embeddings_np = np.array(embeddings).astype('float32')
index.add(embeddings_np)
# Save the index to a file
faiss.write_index(index, index_file_path)
else:
# Load the FAISS index
index = faiss.read_index(index_file_path)
# Read the downloaded text to get paragraphs
with open(text_file_path, 'r', encoding='utf-8') as file:
text = file.read()
paragraphs = split_into_paragraphs(text)
# Function to get top k paragraphs for a query
def get_top_k_paragraphs(query, k=5):
query_embedding = client.embeddings.create(input=query, model="text-embedding-ada-002").data[0].embedding
query_embedding_np = np.array(query_embedding).astype('float32').reshape(1, -1)
distances, indices = index.search(query_embedding_np, k)
top_k_paragraphs = [paragraphs[i] for i in indices[0]]
return top_k_paragraphs
# Function to generate RAG response using GPT-4
def generate_rag_response(query):
top_paragraphs = get_top_k_paragraphs(query)
context = "\n\n".join(top_paragraphs)
prompt = f"Use the following Context to answer the question:\n{context}\n\nQuestion: {query}\n\nAnswer:"
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# Example query to test the RAG pipeline
query = "How much money to make half a dozen boys rich?"
response = generate_rag_response(query)
print(response)
Save this to a file called rag.py.
To run this, you will need to install the Python libraries required
pip install faiss-cpu openai requests numpy packaging
python3 rag.py
And when you run this, you will get the generated Text below:
Six Hundred Dollars
If you’re not familiar with “The Adventures of Tom Sawyer” this is an exact line from the story.
The boys forgot all their fears, all their miseries in an instant. With gloating eyes they watched every movement. Luck!—the splendor of it was beyond all imagination! Six hundred dollars was money enough to make half a dozen boys rich!
So our RAG was able to successfully pull this data out of the story.
There are some great tutorials and blog posts on RAG in general. We won’t duplicate their effort. These include from OpenAI themselves and also FreeCodeCamp. Feel free to reference these if you get lost as we move through this tutorial at any point.
Let’s examine the code above section by section first to make sure we have a fairly straightforward understanding of what it does.
The first section here is where we download our textual corpus and split it into paragraphs. There are multiple ways to chunk text for retrieval. If you have many shorter documents it may be fine to just ingest them as they are. However in our case we have one really long document we are going to split it into paragraphs. If your source material is already segregated by topical sections or topic-based articles then you’re already ahead of the game. Splitting by sentences generally is too granular and will likely miss context.
Python:
import requests
from openai import OpenAI
import os
import faiss
import numpy as np
from concurrent.futures import ThreadPoolExecutor
user_id = 'user123'
# Function to download text from Project Gutenberg
def download_text(url):
response = requests.get(url)
response.encoding = 'utf-8'
response.raise_for_status()
return response.text
# URL for "The Adventures of Tom Sawyer" from Project Gutenberg
url = 'https://www.gutenberg.org/files/74/74-0.txt'
text_file_path = 'tom_sawyer.txt'
index_file_path = 'tom_sawyer_index.faiss'
# Function to save text to a file
def save_text_to_file(text, file_path):
with open(file_path, 'w', encoding='utf-8') as file:
file.write(text)
# Function to split text into paragraphs
def split_into_paragraphs(text):
paragraphs = text.split('\n\n') # splitting character
paragraphs = [p.strip() for p in paragraphs if p.strip()]
return paragraphs
In this next code section we are going to set up the OpenAI Python client as well as create a function to get the embeddings for each paragraph of text. For generating the embeddings we will be using OpenAI’s API and using the text-embedding-ada-002 model. Embeddings are retrieved in parallel to speed up processing.
Python:
# Ensure you have set your OpenAI API key
client = OpenAI(
api_key=os.getenv('OPENAI_API_KEY')
)
# Function to get embeddings for paragraphs
def get_embeddings(paragraphs):
embeddings = []
model_name = "text-embedding-ada-002"
def fetch_embedding(paragraph):
response = client.embeddings.create(input=paragraph, model=model_name)
return response.data[0].embedding
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(fetch_embedding, paragraphs))
return embeddingsThe next code here will store the vectorizations (‘embeddings’) into a local vector database. We will be using Facebook’s Open Source faiss library. At enterprise scale you may be using cloud or hosted vector databases, but the logic is essentially the same.
Here, to avoid having to create the embeddings multiple times we will first check to see if the embeddings file first exists. If it does we will load it and move on to the next part of the process.
If it doesn’t exist, we will download “The Adventures of Tom Sawyer” from Project Gutenberg, split it into paragraphs, generate an embedding from each paragraph using the OpenAI Embeddings API, and then save it to the faiss local vector database. The index that is created is a ‘L2’ distance index, also referred to as the euclidean distance.
Python:
# Check if the FAISS index already exists
if not os.path.exists(index_file_path):
# Download and save the text if it doesn't exist
if not os.path.exists(text_file_path):
text = download_text(url)
save_text_to_file(text, text_file_path)
# Read the downloaded text
with open(text_file_path, 'r', encoding='utf-8') as file:
text = file.read()
# Split the text into paragraphs
paragraphs = split_into_paragraphs(text)
# Generate embeddings for the paragraphs
embeddings = get_embeddings(paragraphs)
# Create a FAISS index
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension) # create L2 distance index
# Convert embeddings to a numpy array and add to the index
embeddings_np = np.array(embeddings).astype('float32')
index.add(embeddings_np)
# Save the index to a file
faiss.write_index(index, index_file_path)
else:
# Load the FAISS index
index = faiss.read_index(index_file_path)
# Read the downloaded text to get paragraphs
with open(text_file_path, 'r', encoding='utf-8') as file:
text = file.read()
paragraphs = split_into_paragraphs(text)
This next function uses OpenAI to create embeddings for the query text, and then search the vector database for the top ‘k’ paragraphs of text that are closest to the embeddings for the query using the euclidean distance index we created previously. You can think of it as the embedding of a paragraph being a point in multidimensional space, and the index is finding the top ‘k’ paragraphs closest to the multi-dimensional point represented by the embedding of the query text. The ‘k’ here defaults to 5 paragraphs.
Python:
# Function to get top k paragraphs for a query
def get_top_k_paragraphs(query, k=5):
query_embedding = client.embeddings.create(input=query, model="text-embedding-ada-002").data[0].embedding
query_embedding_np = np.array(query_embedding).astype('float32').reshape(1, -1)
distances, indices = index.search(query_embedding_np, k)
top_k_paragraphs = [paragraphs[i] for i in indices[0]]
return top_k_paragraphsLastly, we use this code to generate the response for the query. We will gather the top paragraphs according to the embeddings and use them as the context for the question. Once we have built the prompt that includes the query and the context we have pulled from the vector database, we send that prompt to OpenAI’s GPT-4 model to return us a response.
Python:
# Function to generate RAG response using GPT-4
def generate_rag_response(query):
top_paragraphs = get_top_k_paragraphs(query)
context = "\n\n".join(top_paragraphs)
prompt = f"Use the following Context to answer the question:\n{context}\n\nQuestion: {query}\n\nAnswer:"
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# Example query to test the RAG pipeline
query = "How much money to make half a dozen boys rich?"
response = generate_rag_response(query)
print(response)For the example we use here – the prompt generated to the GPT is as follows:
Use the following Context to answer the question: The boys forgot all their fears, all their miseries in an instant. With gloating eyes they watched every movement. Luck!—the splendor of it was beyond all imagination! Six hundred dollars was money enough to make half a dozen boys rich! Here was treasure-hunting under the happiest auspices—there would not be any bothersome uncertainty as to where to dig. They nudged each other every moment—eloquent nudges and easily understood, for they simply meant—“Oh, but ain’t you glad _now_ we’re here!”
The Widow Douglas put Huck’s money out at six per cent., and Judge Thatcher did the same with Tom’s at Aunt Polly’s request. Each lad had an income, now, that was simply prodigious—a dollar for every weekday in the year and half of the Sundays. It was just what the minister got—no, it was what he was promised—he generally couldn’t collect it. A dollar and a quarter a week would board, lodge, and school a boy in those old simple days—and clothe him and wash him, too, for that matter.
But Tom’s energy did not last. He began to think of the fun he had planned for this day, and his sorrows multiplied. Soon the free boys would come tripping along on all sorts of delicious expeditions, and they would make a world of fun of him for having to work—the very thought of it burnt him like fire. He got out his worldly wealth and examined it—bits of toys, marbles, and trash; enough to buy an exchange of _work_, maybe, but not half enough to buy so much as half an hour of pure freedom. So he returned his straitened means to his pocket, and gave up the idea of trying to buy the boys. At this dark and hopeless moment an inspiration burst upon him! Nothing less than a great, magnificent inspiration.
“I judged so; the boys in this town will take more trouble and fool away more time hunting up six bits’ worth of old iron to sell to the foundry than they would to make twice the money at regular work. But that’s human nature—hurry along, hurry along!”
The two men examined the handful of coins. They were gold. The boys above were as excited as themselves, and as delighted.
Question: How much money to make half a dozen boys rich?
Answer:
You can see the paragraphs pulled out of the vector database, including the first, most relevant one that holds the answer to our question.
Feature Measurement and Rollouts
Now that we have a RAG pipeline that we understand, we may want to experiment a bit with some of the parameters to see if we get any appreciable changes to our app metrics. This is where Split comes in. With our powerful calculation engine and easy to use SDKs we can do a bit of experimentation here, changing parts of the code using feature flags.
Let’s first determine which parts of the code to make changes to.
A couple of places immediately come to mind.
First, we can adjust the number of paragraphs of relevant data to pull out of the vector database. Pulling more data adds more context but may muddle the actual responses by providing too much irrelevant information. Pulling too little data may make it not as useful
Second, let’s also adjust the embeddings model. Some embedding models are more expensive than others, and we may want to see if our users’ experiences are degraded by using a cheaper model. Similarly, we can also test with a less expensive GPT model to generate the resulting response.
Creating the Feature Flags in Split
Let’s start by creating the feature flags in Split. We will call them useMoreTextChunks, embeddingsModel, and GPTModel.
We will go through the example for the useMoreTextChunks flag and then you can follow these steps for the other two flags.
First, log in to Split and select your workspace. Click on Create feature flag.
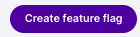
Then you will see this modal pop up – enter the name of the flag and put in an option tag and restrictions. Make sure to select the proper traffic type. In this example we are going to use user with the assumption that our Python code has access to the userID of the user who is interacting with the chatbot, and that this is a feature for logged in users only.
Click Create to create the feature flag.
The last step we need to do is to initialize the flag in our test environment.

Click on Initiate Environment and then save your changes to make the feature flag rules active.
Complete the above steps to also create flags named embeddingsModel and GPTModel
Creating the Flag Rules
Next, let’s go into the flags to create the targeting rules. We will use Split’s Dynamic Configuration in order to be able to experiment with these values without deploying new code. We will store the k_chunks value and model names for both the embeddings and the GPT in Split using this feature.
Let’s start with the useMoreTextChunks flag. Open up the flag’s treatments by clicking on where it says Treatments.

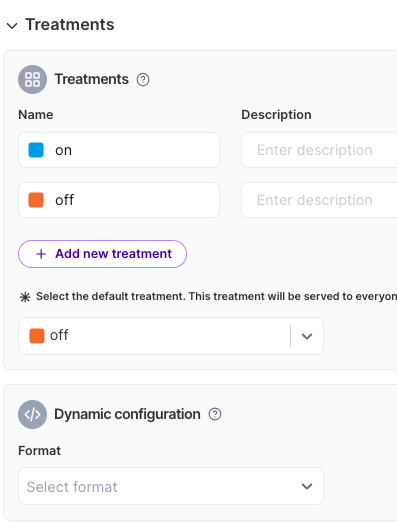
Now let’s add the dynamic configuration. Click on the Select Format box and select Key-value pairs. Then for each treatment (on, and off) click Add new pair and enter k_chunks with a value of 15 for on and a value of 5 for off (our default).
It should look like this:

Now save your changes to the feature flag.
Next, let’s make similar changes to the other flags.
For the GPTModel flag let off be the current gpt-4 model, and let’s have the new (on) treatment be gpt-4o – let’s test to see if 4o has better responses for our questions that make it worth being a bit more expensive.

Save your changes.
Now let’s update the embeddingsModel feature flag to see if we get better embedding results from the text-embedding-3-large model, or if our existing, less expensive model – ada-002 – doesn’t perform appreciably worse for our metrics.
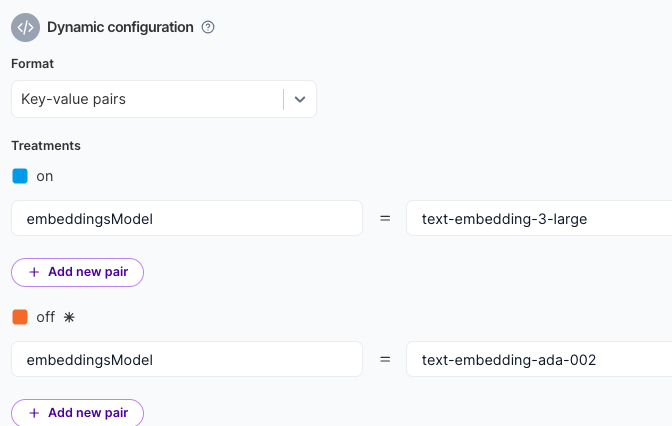
Make sure to save the changes to the feature flag.
Putting the Flags in Code
Now, we will adjust our code to include these flags, including the Split Python SDK.
Let’s first install the Split SDK in our project.
pip install 'splitio_client[cpphash]==9.6.1'Now let’s go into the code and instantiate the Split SDK. Notice that in addition to importing the Split libraries we are also importing json in order to allow us to read the dynamic configuration key-value pairs we just stored into the feature flags above. This also requires that we put our Split SDK key into an environment variable called SPLIT_SDK_KEY.
Python:
from splitio import get_factory
from splitio.exceptions import TimeoutException
import json # need this for dynamic config
factory = get_factory(os.getenv('SPLIT_SDK_KEY'), config={'impressionsMode': 'OPTIMIZED'})
try:
factory.block_until_ready(5) # wait up to 5 seconds
except TimeoutException:
# insert code here for when the SDK times out
pass
splitClient = factory.client()
user_id = 'user123'Now that the SDK is ready, let’s adjust the code to make this work. First, let’s adjust the code for the ‘top k embeddings’ to use the value stored in the feature flag.
Let’s adjust the function where we call our get_top_k_paragraphs function to include using the Split SDK and reading from the dynamic configuration to retrieve the ‘k’ value. As always is best practice, we should ensure we handle the case that the SDK cannot connect for some reason, and as such we will program defensively and support the case where config is an empty object.
Python:
# Function to generate RAG response
def generate_rag_response(query):
text_chunks_treatment, text_chunks_raw_config = splitClient.get_treatment_with_config(user_id, 'useMoreTextChunks')
text_chunks_config = json.loads(text_chunks_raw_config) if text_chunks_raw_config is not None else {}
if 'k_chunks' in text_chunks_config:
top_paragraphs = get_top_k_paragraphs(query, k=int(text_chunks_config['k_chunks']))
else:
top_paragraphs = get_top_k_paragraphs(query)
context = "\n\n".join(top_paragraphs)
prompt = f"Use the following Context to answer the question:\n{context}\n\nQuestion: {query}\n\nAnswer:"
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Now that we’re here in this function, this is also where we’d change the GPT model used to generate the response. Here we can further adjust the code in this function to use what we have configured in the feature flag.
Python:
# Function to generate RAG response
def generate_rag_response(query):
text_chunks_treatment, text_chunks_raw_config = splitClient.get_treatment_with_config(user_id, 'useMoreTextChunks')
text_chunks_config = json.loads(text_chunks_raw_config) if text_chunks_raw_config is not None else {}
if 'k_chunks' in text_chunks_config:
top_paragraphs = get_top_k_paragraphs(query, k=int(text_chunks_config['k_chunks']))
else:
top_paragraphs = get_top_k_paragraphs(query)
context = "\n\n".join(top_paragraphs)
prompt = f"Use the following Context to answer the question:\n{context}\n\nQuestion: {query}\n\nAnswer:"
model_treatment, model_raw_config = splitClient.get_treatment_with_config(user_id, 'GPTModel')
model_config = json.loads(model_raw_config) if model_raw_config is not None else {}
if 'GPTModel' in model_config:
GPTModel=model_config['GPTModel']
else:
GPTModel='gpt-4'
response = client.chat.completions.create(
model=GPTModel,
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Now let’s do something a bit more complicated in changing our embeddings model. So one thing to notice is that we saved the embeddings to a file. If we were to re-run the embeddings we would have different embeddings due to a potentially different embeddings model. To get around this we are going to prepend the model name to the embeddings file in order to make sure that we can still cache and avoid having to create the same embeddings over and over again.
Python:
embeddings_treatment, embeddings_raw_config = splitClient.get_treatment_with_config(user_id, 'embeddingsModel')
embeddings_config = json.loads(embeddings_raw_config) if embeddings_raw_config is not None else {}
if 'embeddingsModel' in embeddings_config:
embeddings_model = embeddings_config['embeddingsModel']
else:
embeddings_model='text-embedding-ada-002'
# URL for "The Adventures of Tom Sawyer" from Project Gutenberg
url = 'https://www.gutenberg.org/files/74/74-0.txt'
text_file_path = 'tom_sawyer.txt'
index_file_path = f"{embeddings_model}_tom_sawyer_index.faiss"Now we also need to update the get_embeddings function and the get_top_k_paragraphs functions to read in the embeddings model we just defined.
# Function to get top k paragraphs for a query
def get_top_k_paragraphs(query, k=5, embeddings_model=embeddings_model):
query_embedding = client.embeddings.create(input=query, model=embeddings_model).data[0].embedding
query_embedding_np = np.array(query_embedding).astype('float32').reshape(1, -1)
distances, indices = index.search(query_embedding_np, k)
top_k_paragraphs = [paragraphs[i] for i in indices[0]]
return top_k_paragraphsAnd for get_embeddings
# Function to get embeddings for paragraphs
def get_embeddings(paragraphs, embeddings_model=embeddings_model):
embeddings = []
model_name = embeddings_model
def fetch_embedding(paragraph):
response = client.embeddings.create(input=paragraph, model=model_name)
return response.data[0].embedding
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(fetch_embedding, paragraphs))
return embeddingsPutting it all together
Here’s what the final code looks like with the feature flags integrated into it.
Python:
import requests
from openai import OpenAI
import os
import faiss
import numpy as np
from concurrent.futures import ThreadPoolExecutor
from splitio import get_factory
from splitio.exceptions import TimeoutException
import json # need this for dynamic config
factory = get_factory(os.getenv('SPLIT_SDK_KEY'), config={'impressionsMode': 'OPTIMIZED'})
try:
factory.block_until_ready(5) # wait up to 5 seconds
except TimeoutException:
# Now the user can choose whether to abort the whole execution, or just keep going
# without a ready client, which if configured properly, should become ready at some point.
pass
splitClient = factory.client()
user_id = 'user123'
# Function to download text from Project Gutenberg
def download_text(url):
response = requests.get(url)
response.encoding = 'utf-8'
response.raise_for_status()
return response.text
embeddings_treatment, embeddings_raw_config = splitClient.get_treatment_with_config(user_id, 'embeddingsModel')
embeddings_config = json.loads(embeddings_raw_config) if embeddings_raw_config is not None else {}
if 'embeddingsModel' in embeddings_config:
embeddings_model = embeddings_config['embeddingsModel']
else:
embeddings_model='text-embedding-ada-002'
# URL for "The Adventures of Tom Sawyer" from Project Gutenberg
url = 'https://www.gutenberg.org/files/74/74-0.txt'
text_file_path = 'tom_sawyer.txt'
index_file_path = f"{embeddings_model}_tom_sawyer_index.faiss"
# Function to save text to a file
def save_text_to_file(text, file_path):
with open(file_path, 'w', encoding='utf-8') as file:
file.write(text)
# Function to split text into paragraphs
def split_into_paragraphs(text):
paragraphs = text.split('\n\n')
paragraphs = [p.strip() for p in paragraphs if p.strip()]
return paragraphs
# Ensure you have set your OpenAI API key
client = OpenAI(
api_key=os.getenv('OPENAI_API_KEY')
)
# Function to get embeddings for paragraphs
def get_embeddings(paragraphs, embeddings_model=embeddings_model):
embeddings = []
model_name = embeddings_model
def fetch_embedding(paragraph):
response = client.embeddings.create(input=paragraph, model=model_name)
return response.data[0].embedding
with ThreadPoolExecutor() as executor:
embeddings = list(executor.map(fetch_embedding, paragraphs))
return embeddings
# Check if the FAISS index already exists
if not os.path.exists(index_file_path):
# Download and save the text if it doesn't exist
if not os.path.exists(text_file_path):
text = download_text(url)
save_text_to_file(text, text_file_path)
# Read the downloaded text
with open(text_file_path, 'r', encoding='utf-8') as file:
text = file.read()
# Split the text into paragraphs
paragraphs = split_into_paragraphs(text)
# Generate embeddings for the paragraphs
embeddings = get_embeddings(paragraphs)
# Create a FAISS index
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
# Convert embeddings to a numpy array and add to the index
embeddings_np = np.array(embeddings).astype('float32')
index.add(embeddings_np)
# Save the index to a file
faiss.write_index(index, index_file_path)
else:
# Load the FAISS index
index = faiss.read_index(index_file_path)
# Read the downloaded text to get paragraphs
with open(text_file_path, 'r', encoding='utf-8') as file:
text = file.read()
paragraphs = split_into_paragraphs(text)
# Function to get top k paragraphs for a query
def get_top_k_paragraphs(query, k=5, embeddings_model=embeddings_model):
query_embedding = client.embeddings.create(input=query, model=embeddings_model).data[0].embedding
query_embedding_np = np.array(query_embedding).astype('float32').reshape(1, -1)
distances, indices = index.search(query_embedding_np, k)
top_k_paragraphs = [paragraphs[i] for i in indices[0]]
return top_k_paragraphs
# Function to generate RAG response
def generate_rag_response(query):
text_chunks_treatment, text_chunks_raw_config = splitClient.get_treatment_with_config(user_id, 'useMoreTextChunks')
text_chunks_config = json.loads(text_chunks_raw_config) if text_chunks_raw_config is not None else {}
if 'k_chunks' in text_chunks_config:
top_paragraphs = get_top_k_paragraphs(query, k=int(text_chunks_config['k_chunks']))
else:
top_paragraphs = get_top_k_paragraphs(query)
context = "\n\n".join(top_paragraphs)
prompt = f"Use the following Context to answer the question:\n{context}\n\nQuestion: {query}\n\nAnswer:"
model_treatment, model_raw_config = splitClient.get_treatment_with_config(user_id, 'GPTModel')
model_config = json.loads(model_raw_config) if model_raw_config is not None else {}
if 'GPTModel' in model_config:
GPTModel=model_config['GPTModel']
else:
GPTModel='gpt-4'
response = client.chat.completions.create(
model=GPTModel,
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# Example query to test the RAG pipeline
query = "How much money to make half a dozen boys rich?"
response = generate_rag_response(query)
print(response)Now we run it with our current setup, since all of our defaults are the values that existed before, we run it and we’ll get the same response.
Six Hundred DollarsLet’s play around with the feature flags to see if we get a different response. If we turn GPTModel to on – let’s see if we get a different response from GPT-4o:
(make sure to save the flag change!)
Six hundred dollars was money enough to make half a dozen boys rich.Looks like here we get some more context back using the new model.
Cool – now let’s turn the embeddingsModel flag on as well and see if that changes anything to use the more expensive embeddings model:
Six hundred dollars was money enough to make half a dozen boys rich.Seems like for this question the embeddings model didn’t have any effect.
Let’s change the question and see – maybe having a straightforward question doesn’t get strongly affected by these things.
If we change this line:
query = "Who is Joe Harper?"We get this answer:
Joe Harper is a character mentioned in the context who seems to be a friend or acquaintance of Tom. He is described as being similarly dressed and equipped as Tom and is addressed by someone asking if he has seen Tom that morning. Joe Harper appears in response to these inquiries.Now let’s turn embeddingsModel off and see if there is a difference here.
And we do get a different answer:
Joe Harper is a character who is associated with Tom in the given context. He is described as being dressed and armed similarly to Tom, indicating that he is likely a close companion or friend of Tom. Additionally, there appears to be mention of Joe Harper’s mother, suggesting that Joe Harper is also important enough to be referenced in dreams by someone else.Keep playing around and change the prompt and the flags to see if you get any different responses – you’ll see how altering these configuration parameters can have a strong effect on the text produced by the GPT model without needing to change any of the code.
Where to go from here
When hooking this up to a production workload with real user IDs – you may also want to explore percentage based rollouts in order to do the math to really measure the feature impact.

Using the flags we just enabled you can see the power of using Split in concert with its dynamic configuration to be able to control the RAG pipeline with just a click of a button and a few keystrokes in the Split Web Console. Go further from here and create metrics, set up percentage based rollouts and send events to Split. With our IFID Capability we can handle measurement for any number of concurrent experiments and pinpoint the winners and the losers, alerting you when they’ve hit significance.
We can’t wait to see what you’re capable of with Split and Generative AI.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today or Schedule a demo to learn more.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.