
If you haven’t read, large language model (LLM) based artificial intelligence tools have had an enormous impact on almost every industry and have taken the world by storm. From software engineers to artists, accountants, consultants, writers, and more. It’s an incredible tool that extends the creative power of humanity.
That’s a pretty weighty intro, true, but it’s undeniable how AI is changing the world. But if you want to implement AI into your own application, you should do it carefully, and with thoughtfulness. There is no need to move fast and break things, but rather, move fast with safety.
Using feature flags with AI allows you to test and measure the impact of AI on your metrics. AI tools can assist you in many fields, but you do need actual data on the outcomes that it is supposed to improve for you. For that, you need hard, statistically significant data.
This is where Split comes into play. Our measurement and learning capabilities can help you evaluate AI based approaches and iterate, ensuring that you can rapidly determine, with safety, which is best.
Some popular implementations include Google’s Bard, Microsoft’s Bing, and OpenAI’s ChatGPT.
Let’s look at some code using OpenAI in Python:
import openai
openai.api_key = "API_KEY"
completion = openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
temperature = 0.8,
max_tokens = 2000,
messages = [
{"role": "system", "content": "You are a comedian that tells funny computer jokes."},
{"role": "user", "content": "Write a funny joke related to computers."},
{"role": "assistant", "content": "Q:Why did the computer go to the doctor? A: Because it had a virus."},
{"role": "user", "content": "Write another funny joke."}
]
)
print(completion.choices[0].message)This is a pretty basic piece of code. This will have OpenAI’s Chat GPT write a funny computer joke.
In this case, it wrote for me:
Why do programmers prefer dark mode? Because the light attracts too many bugs.Now, let’s say you want to modify the parameters, such as changing the temperature, the maximum number of tokens, or even the language model itself! These are parameters that OpenAI’s ChatGPT uses to fine tune the AI and what it provides in response to your prompts. We can store this information in Split’s handy Dynamic Configuration to allow modifying these from the Split UI without needing to deploy any new code.
To do this, first, let’s create a flag, we’ll call it AI_FLAG for this scenario:
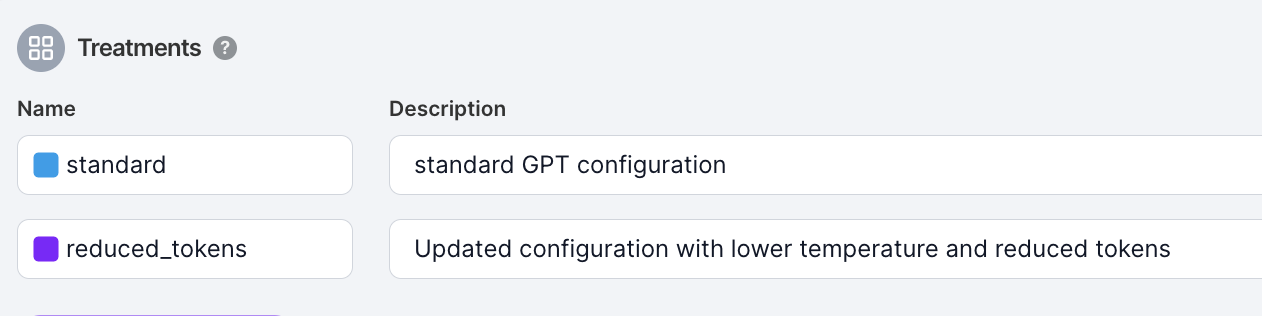
We’ll give it two treatments that we want to test our AI parameters with. A standard treatment with the standard configuration, and a reduced_tokens treatment with a reduced number of tokens and a lower temperature.
ChatGPT’s temperature setting is the setting for the balance between factuality and creativity in the language mode. A higher temperature value means the AI gets to be more creative with responses, whereas a lower temperature means it will stick primarily to fact based knowledge that it has. It can range from zero to one. The maximum tokens setting is the maximum length of a response that ChatGPT can give you.
Now let’s create some dynamic configuration using key value pairs to hold the model, max_tokens, and temperature:
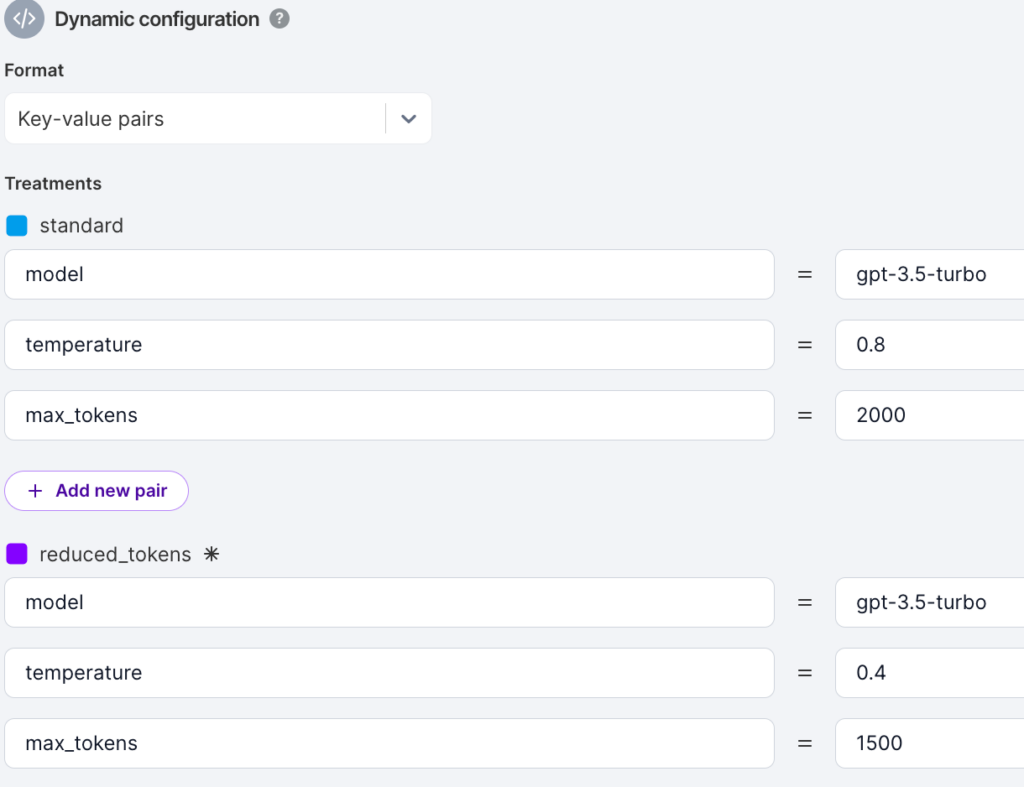
Then let’s hook up the parameters into the code using the Split SDK’s dynamic configuration to set the parameters. Note here that the different experiences are not actually based upon the name of the treatment, but rather the dynamic configuration contained within the Split web console. This is an extremely powerful set up, where parameters can be constantly iterated upon without needing to deploy any new code!
import openai
from splitio import get_factory,client
import json
openai.api_key = "API_KEY"
factory = get_factory('SPLIT_KEY', config= {'impressionsMode':'optimized'})
try:
factory.block_until_ready(5) # wait up to 5 seconds
except TimeoutException:
# Handle the timout here
pass
client = factory.client()
treatment, raw_config = client.get_treatment_with_config('USER_KEY', 'AI_FLAG')
configs = json.loads(raw_config)
completion = openai.ChatCompletion.create(
model = configs['model'],
temperature = configs['temperature'],
max_tokens = configs['max_tokens'],
messages = [
{"role": "system", "content": "You are a comedian that tells funny computer jokes."},
{"role": "user", "content": "Write a funny joke related to computers."},
{"role": "assistant", "content": "Q:Why did the computer go to the doctor? A: Because it had a virus."},
{"role": "user", "content": "Write another funny joke."}
]
)
print(completion.choices[0].message)With an even more sophisticated approach, you could contain the training prompts within the Split dynamic configuration itself. This would be a highly advanced configuration but would allow not only parameterizing and iterating over the model and configuration, but also the training data. With the prompts in Split you have almost infinite possibilities for testing and iterating over AI setup.
Here is what that could look like as dynamic configuration
For this you would have to use the JSON as the dynamic configuration option.
In this example we have two treatments for this feature flag, one named chicken_jokes and one named computer_jokes—we want to see if our customers like chicken jokes instead of computer jokes. We can completely customize the prompts using dynamic configuration. Here is what the JSON could look like:
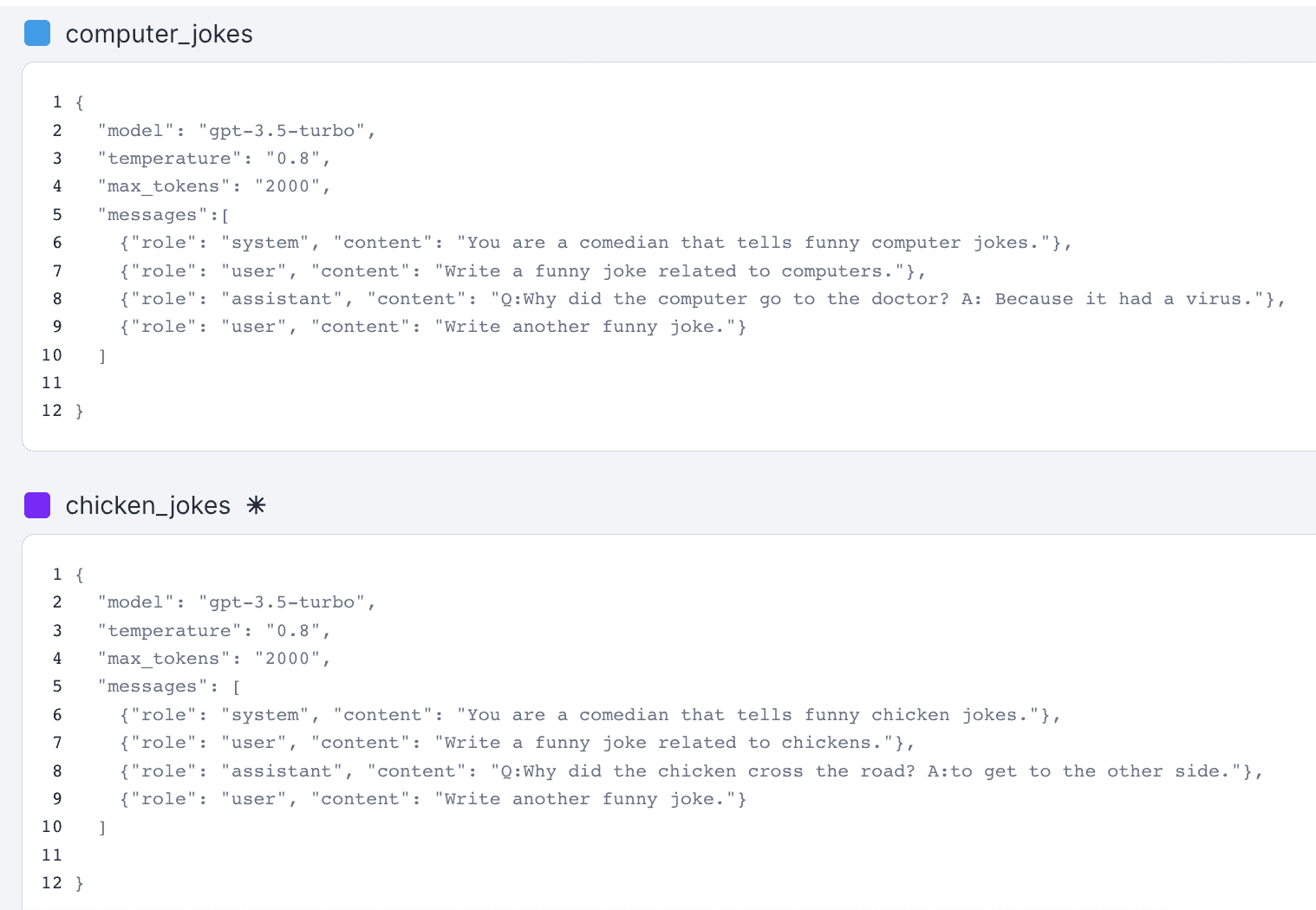
And in the code we would simply set the messages object to messages in the ChatGPT configuration:
import openai
from splitio import get_factory,client
import json
openai.api_key = "API_KEY"
factory = get_factory('SPLIT_KEY', config= {'impressionsMode':'optimized'})
try:
factory.block_until_ready(5) # wait up to 5 seconds
except TimeoutException:
# Handle the timout here
pass
client = factory.client()
treatment, raw_config = client.get_treatment_with_config('USER_KEY', 'AI_FLAG')
configs = json.loads(raw_config)
completion = openai.ChatCompletion.create(
model = configs['model'],
temperature = configs['temperature'],
max_tokens = configs['max_tokens'],
messages = configs['messages']
)
print(completion.choices[0].message)Run this and your code will print out either a chicken joke or a computer joke, depending completely on the dynamic configuration cached from Split based upon the treatment the user has received.
This is an incredibly powerful example of how Split can be used in testing and validating AI models, allowing for extremely rapid iteration and learning.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
Split gives product development teams the confidence to release features that matter faster. It’s the only feature management and experimentation platform that automatically attributes data-driven insight to every feature that’s released—all while enabling astoundingly easy deployment, profound risk reduction, and better visibility across teams. Split offers more than a platform: It offers partnership. By sticking with customers every step of the way, Split illuminates the path toward continuous improvement and timely innovation. Switch on a trial account, schedule a demo, or contact us for further questions.